关于Chromium内核浏览器扩展开发草稿
其实我从来没有想过要写浏览器扩展的。一是因为感觉浏览器扩展的本身用武之地不大,二是感觉这小小的扩展说不定写起来还很麻烦,所以一直没有想过要写这个玩意儿。但是世间之事是真的巧,一个在实习的老哥的工作流程恰好可以通过浏览器扩展来极大的加速。他委托我帮他搞一个扩展,我也抱着试一试的心理,尝试了一下。让我自己都觉得意外,浏览器扩展上手真的是比我想象的还要简单。在此也记录一下在开发过程中的一些关键概念和碰到的坑,以备后用。
基于Chromium内核的浏览器扩展
标签页与扩展的独立性
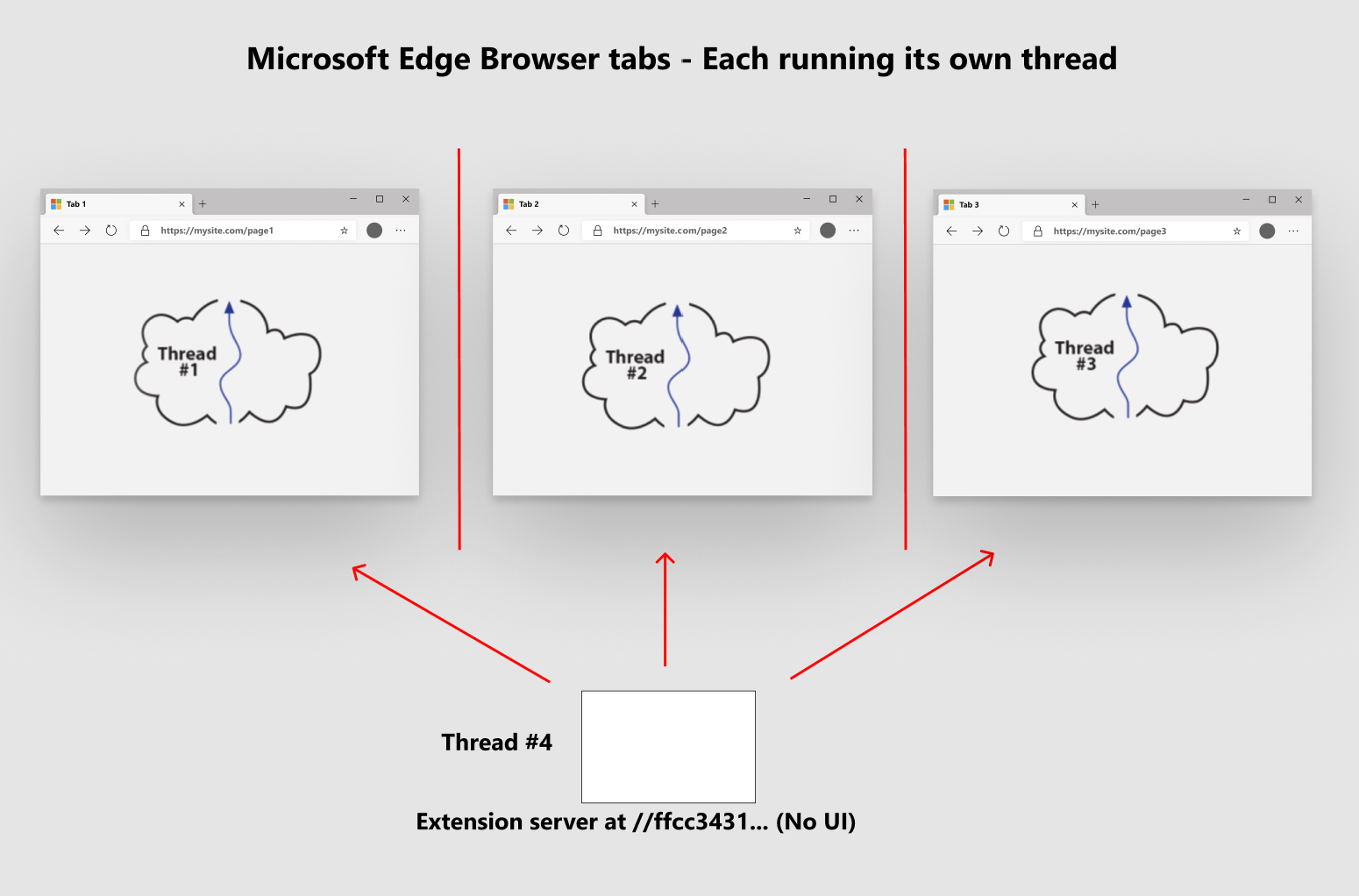
如图所示Chromium的浏览器中,每个标签页都是一个隔离的进程,它们之间并不互通信息。每个标签页与服务器之间的都是有着独立的网络通信的。
扩展,则更像是一个服务器的角色。安装一个扩展,就是在浏览器中创建了一个独立的Web服务器。当然,这个扩展的服务器也是与标签页隔离的。我们如果要编写扩展和标签页交互的话,是需要使用到标准的Chrome API来与标签页进行交互的。
扩展的文件结构
一个浏览器扩展,实质上一组网络资源(a bundle of web resources),包括html、css、js和图像等等文件,很类似于被发布到web服务器的资源。它们以zip压缩包的形式发布——当然开发的时候你只需要进行旁加载一个未压缩的文件夹。在这个文件夹中,还有一个叫做manifest.json的清单文件。清单文件是扩展的蓝图,包括扩展的版本、标题、运行扩展所需的权限等。
启动扩展服务器
一个服务器扩展被使用时,(如果它具有index.html),那么浏览器会使用extension://{some-long-unique-identifier}/index.html中的文件来提供服务。其中{some-long-unique-identifier}在安装期间分配给扩展的唯一标识符。每个扩展使用不同的唯一标识符。每个标识符都指向在浏览器中安装的 Web 捆绑包。
权限必须在使用前在
manife.json中注明,否则浏览器不认为这个扩展具有相应的权限。
以一个例子来介绍扩展内部
功能需求
回到这篇文章的顶部,我们先来谈一下需求。现在是这个老哥打开了许多相同的功能页面,只是每个页面对应的用户不同。他需要做的事就是点击每个页面的“全选”,再点击“下载”。也就是说,我们需要获取到当前所有加载完的一类(具有相同路径前缀)标签页,再对每一个标签页进行一步全选并下载的操作即可。
文件结构及其作用
这个小扩展其实很简单,根目录下一共三个文件一个文件夹,分别是:
manifest.json清单文件,每个扩展必要的文件。其中记录了一些必要的属性,包括不限于扩展的名称、版本、manifest_version、介绍、作者、国际化、图标、权限、重要文件等等内容。其中,扩展的名称、版本和manifest_verison是必须字段。background.js是扩展事件的处理程序(service worker)。它包括扩展对浏览器事件的所有监听器,并对事件做出响应。对于backgroud: {serviceworker: "..."}的指定也是必须字段。content.js是具体注入到特定选项卡页面中的javascript脚本。icons/文件夹如其名,包含图标文件。一般为16、32、48、128的正方形png文件。不能是svg文件。
manifest.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"name": "Open links",
"version": "1.0",
"manifest_version": 3,
"author": "Michael Tan",
"homepage_url": "https://www.michaeltan.org",
"description": "Designed for automatically download pictures in specific pages.",
"action": {
"default_title": "Download as many as you want"
},
"icons": {
"16": "icons/robot-arm-icon-16.png",
"128": "icons/robot-arm-icon-128.png"
},
"commands": {
"download": {
"suggested_key": {
"default": "Ctrl+Shift+Y",
"mac": "Command+Shift+Y"
},
"description": "Automatically dowaload all pictures.",
"global": true
}
},
"permissions": [
"activeTab",
"scripting",
"tabs"
],
"host_permissions": [
"http://[hidden url]/Image/app/h5img.*"
],
"background": {
"service_worker": "background.js"
}
}
如上所示,manifest.json主要记录描述性信息。其中action字段主要控制在控制栏的扩展图标的内容和状态,包括不限于图标本身、badge、tooltip、enable/disable等等。我们这里只用了一个default_title显示一个tooltip。
可以看到,manifest.json中记录了许多除了描述信息以外的其他内容。其中commands记录了快捷键功能的设置。其中定义了一个叫做download的快捷键组合,并设置了推荐的快捷键(用户可以修改为它们想要的功能),global:true则是将提供在浏览器没有聚焦时仍具有响应(Global commands also work while Chrome does not have focus.)。permissions则声明了该扩展所需的权限,activeTab是操作当前页面内容的权限(严格来说并不需要,是因为我们不仅仅只操作当前页面,但是我们所进行的事件监听需要改权限),scripting是在页面中运行脚本所需的权限,tabs提供了读取当前浏览器所有选项卡的权限。host_permissions提供了需要读取页面内容的url。最后的background指定了常驻的事件监听代码。
完整的manifest.json格式说明可以在谷歌的开发文档中找到。
background.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
chrome.action.onClicked.addListener((_) => {
chrome.tabs.query(
{
url: "http://[hidden url]/Image/app/h5img.*",
status: 'complete'
},
(Tab) => {Tab.forEach(tab => {
chrome.scripting.executeScript({
target: {tabId: tab.id},
files: ['content.js']
})
})}
)
});
chrome.commands.onCommand.addListener((command) => {
(command === 'download') && chrome.tabs.query(
{
url: "http://[hidden url]/Image/app/h5img.*",
status: 'complete'
},
(Tab) => {Tab.forEach(tab => {
chrome.scripting.executeScript({
target: {tabId: tab.id},
files: ['content.js']
})
})}
)
})
如上所示,该扩展有两个事件监听器。一个是对于扩展的图标被点击的事件,另一个是对于快捷键download被激活的事件。两个事件的行为是相似的,都是往当前所有被筛选出的页面中,运行content.js中的代码段。其中第一个事件,被省略的传入参数实际上是一个tab,对应的当前的页面,也就是activeTab权限被声明的原因。当图标被选中后,扩展根据url和网页的状态(unloaded、loading、complete)查询到相关的网页。chrome.tabs.query的具体使用既可以通过处理Promise,也可以像这里通过回调函数来使用。返回的是一个Tab[]数组。我们对每一个Tab[]中的对象注入我们需要的代码即可。chrome.scripting.excuteScript同上个API一样,同样可以在回调函数和Promise中二选一进行处理,不过在这里没有使用。
1
2
3
4
chrome.scripting.executeScript(
injection: ScriptInjection,
callback?: function,
)
这里的ScriptInjection部分才是我们真正使用到的。ScriptInjection中必须指定的即是target,它是一个InjectionTarget对象,其中tabId是必须项。ScriptInjection中还有两个二选一的必选项,分别是示例中的files,以及func。这里为了方便划分功能,我们采用了文件形式,将对单个页面的处理代码保存在了content.js中。
content.js
1
2
3
4
var selectAll = document.querySelector('div[id="all-btn"]');
selectAll.click()
var download = document.querySelector('a[id="download"]');
download.click()
大可不必再费口舌介绍。
一些额外的想法
我们在注入页面的功能代码content.js的时候,使用的是动态注入。开发文档中还提供了一种静态注入的方法。相对于动态注入来说,静态注入的代码量要少得多。
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"name": "My extension",
...
"content_scripts": [
{
"matches": ["https://*.nytimes.com/*"],
"css": ["my-styles.css"],
"run_at": "document_idle",
"js": ["content-script.js"]
}
],
...
}
但是自动执行的静态注入不方便控制注入的时机。虽然可以使用run_at字段来控制代码片段的执行时间,但是为了避免过多的测试,本次扩展的编写过程没有使用静态注入。run_at可以是document_start、document_end以及document_idle。可以使用一下两种方式修改静态注入的时机。
1
2
3
4
5
6
7
8
9
10
11
12
{
"name": "My extension",
...
"content_scripts": [
{
"matches": ["https://*.nytimes.com/*"],
"run_at": "document_idle",
"js": ["contentScript.js"]
}
],
...
}
1
2
3
4
5
chrome.scripting.registerContentScript({
matches: ['https://*.nytimes.com/*'],
run_at: 'document_idle',
js: ['contentScript.js']
});